



Finetuning or Not? Open vs. Proprietary LLMs
Open AI Models vs. Proprietary Models at a Glance
In the rapidly evolving field of artificial intelligence, the trend toward open models is gaining significant momentum. Major tech giants like Meta and Mistral are pioneering this movement, with even Google joining the fray by opening up more with its Gemini project. But why is the openness of AI models such a crucial component for fostering innovation?
The Rise of Open Models
The concept of open AI models revolves around making the underlying models and data accessible to a wider community. This transparency enables researchers and developers to build upon existing frameworks, thus accelerating the pace of innovation. One of the key players in this domain is BigScience, a collaborative initiative aimed at creating a counterpart to OpenAI's GPT-3. This project brought together over 1,000 collaborators and spanned 59 languages, utilizing a massive 350 billion token dataset. The resulting model, with its 176 billion parameters, was trained on a French supercomputer, illustrating the scale and complexity involved in such endeavors.
Switzerland's Alps Supercomputers: The Backbone of Open Model Training
Training large open models requires substantial computational power, often provided by supercomputers. Switzerland’s own Alps supercomputer is a prime example, offering the necessary infrastructure to handle the extensive processing demands. These supercomputers facilitate the use of advanced parallelism techniques essential for efficient model training.
What is the Difference between Finetuning and Prompt Engineering?
Finetuning requires modifying the pre-trained model's parameters to adapt it to a specific task, whereas prompt engineering adjusts the input prompts to guide the model's output without altering its parameters. The need for finetuning depends on the circumstances and use case you are facing. Ask yourself first:
- For instance, are you using models in a cloud environment? Then you can also do finetuning on a cloud-environment. Keep in mind: Not all models or types (e.g. GPT-4o) are available for fintetuning with cloud providers.
- For instance, if you are using models in a cloud environment, extensive GPU or TPU resources are necessary for finetuning. These resources can be provided by your cloud provider or set up in your hosting environment.
- If you cannot buy GPUs you can use Consumer GPUs (GTX 3080). Usually you do not train a model from scratch as this takes weeks.
- Alternatively, you can buy processing power on virtual machines such as vast.ai which is cheaper for first experiments with finetuning models.
When to Use Finetuning?
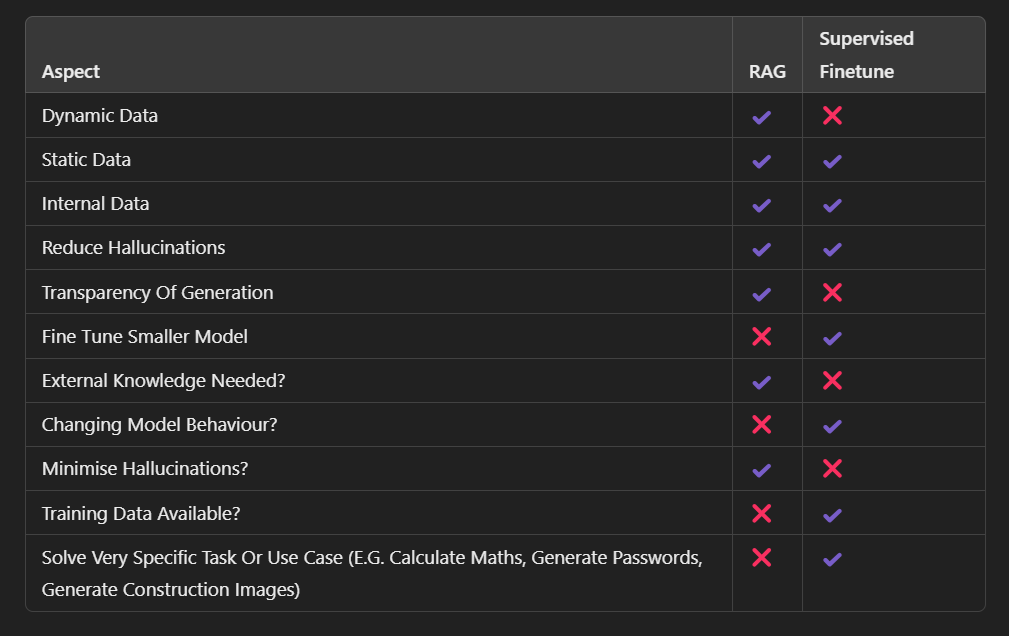
Finetuning and Retrieval-Augmented Generation (RAG) are two different approaches for improving the performance of language models. Here's when to use finetuning:
1. Specific Knowledge Domain: If your task requires a deep understanding of a specific domain with specialized terminology or context, finetuning a model on a relevant dataset can significantly improve performance.
2. Task-Specific Adaptation: For tasks like sentiment analysis, text classification, named entity recognition, or other specific NLP tasks, finetuning allows the model to learn patterns and nuances unique to that task.
3. Custom Outputs: When you need the model to generate very specific types of responses or outputs that are not well-captured by a general model, finetuning helps tailor the responses.
4. Consistent Performance: If you require consistent and reliable performance on a particular task, finetuning ensures the model is optimized for that specific task, leading to more predictable results.
When is RAG (Retrieval-Augmented Generation) Enough?
1. Broad Information Retrieval: If your task involves answering questions, generating text based on external documents, or requiring up-to-date information, RAG is useful as it combines a generative model with a retrieval mechanism to fetch relevant documents.
2. Dynamic Knowledge Updates: When the information changes frequently or the task requires access to a large and dynamic knowledge base, RAG can pull in the most current and relevant information at the time of the request without needing to retrain the model.
3. Low Resource Availability: If you lack the computational resources or large, high-quality datasets necessary for finetuning, RAG can still provide high-quality outputs by leveraging external knowledge sources.
4. General Purpose Use: For more general-purpose applications where the model needs to handle a wide range of topics and the precise tailoring of responses is less critical, RAG can be sufficient and more efficient.
Use finetuning when you need highly specialized, task-specific, and consistent performance, and you have the necessary resources and data for training. Use RAG when you need flexible, up-to-date information retrieval and generation capabilities, especially if you lack the resources for extensive model training.
When RAG is not Enough?
RAG can be limited, especially if you want to build models that are very specific for a certain task (e.g., generating passwords). RAG can be constrained by the context window of the underlying model, which limits the amount of data or number of articles it can effectively use for generating responses. The retrieved documents are integrated into the prompt, affecting the model's performance and context management.
What do you Need to Consider for Model Training When Doing Finetuning?
In order to calculate all parameters (weights) - since not all parameters can be processed on a single GPU - fast parallel processing is needed. There are specific methods for achieving this:
1. 3D Parallelism: This method distributes data across multiple GPUs, allowing each instance to handle a different chunk of the dataset.
2. Pipeline Parallelism: Here, different layers of the neural network are assigned to different GPUs, ensuring a balanced load across the system.
3. Tensor Parallelism: This technique slices the computational tasks horizontally across the layers, distributing matrix multiplication tasks among various GPUs.
A significant challenge in training open models is acquiring a robust and diverse dataset. BigCode tackled this by leveraging the GitHub Archive to collect the names of over 200 million repositories. The process involved several months of cloning repositories, followed by meticulous filtering to remove binary data and irrelevant files. The final dataset, amassing 3 terabytes of data, aimed to rival the quality of models like GitHub's Copilot.
Empowering the AI Community Through Open Models
Open models democratize the field of AI, empowering a broader community to fine-tune these models for specific use cases. This approach leads to the creation of smaller, more affordable models tailored to particular needs, driving innovation at a grassroots level. By providing the tools and frameworks needed to adapt and improve AI models, the community can explore a myriad of applications, from language translation to specialized industry solutions.
Conclusion
The push towards open AI models represents a pivotal shift in the AI landscape. By leveraging the power of supercomputers and collaborative efforts, the development of open models is not only feasible but also immensely beneficial. As more organizations and researchers join this movement, the potential for innovation expands exponentially, heralding a future where AI technology is more accessible, adaptable, and capable of addressing a diverse array of challenges.
Need support with your Generative Ai Strategy and Implementation?
🚀 AI Strategy, business and tech support
🚀 ChatGPT, Generative AI & Conversational AI (Chatbot)
🚀 Support with AI product development
🚀 AI Tools and Automation










talk(at)voicetechhub.com
Etzbergstrasse 37, 8405 Winterthur
©VOOCE GmbH 2019 - 2025 - All rights reserved.
SWISS MADE. SWISS ENGINEERING.